Mozilla’s Open Source Speech Recognition Model and Voice Dataset
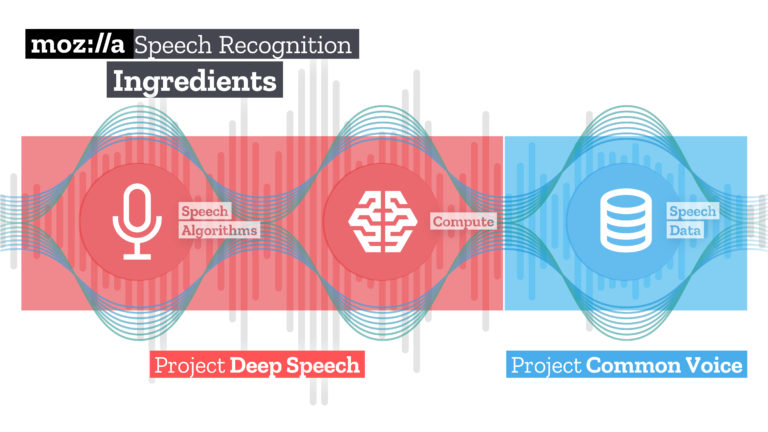
Mozilla has just announced the initial release of Mozilla’s open source speech recognition model that has an accuracy approaching what humans can perceive when listening to the same recordings. They are also releasing the world’s second-largest publicly available voice dataset, which was contributed to by nearly 20,000 people globally. This looks like it will be a very useful resource for researchers.

No comments:
Post a Comment